Hvordan er kvaliteten af en automatiseret oversættelse genereret via ChatGPT? Er det overhovedet muligt at undersøge det?
Det følgende er en empirisk-eksperimentel undersøgelse af, i hvilket omfang generativ kunstig intelligens er i stand til at genskabe et science fiction-værks hensigt og betydningspotentiale i en promptet oversættelse.
Af Nicolai Thomas Hansen
Generativ kunstig intelligens (GAI), også kaldet AI-chatbots, har været et varmt emne lige siden ChatGPT blev udgivet i 2022. De er i stand til mange forskellige handlinger, og oversættelse er selvfølgelig en af dem. Det har ført til en del undersøgelser af kvaliteten af GAI-oversættelse, men for det meste har det været i forbindelse med generelle og tekniske tekster. Hvad med skønlitteratur? Der er nogle danske forlag, som nemlig allerede har anvendt eller prøvet kræfter med GAI til at oversætte bøger og så hyret oversættere til at efterredigere og rette fejl [i]. Er der måske noget om snakken?
Det skrev jeg om i mit speciale. For at undersøge kvaliteten af GAI-oversættelse fokuserede jeg på science fiction-genren, da det kan være udfordrende at oversætte værker af denne type, fordi der typisk findes neologismer og opdigtet teknologi, hvor man ikke bare kan slå op i en ordbog – man skal bruge sin fantasi og kreativitet i oversættelsesprocessen. Desuden er genren kommet på mode i dag – der har f.eks. været de to filmatiseringer af Dune-bøgerne i 2021 og 2024, og der er kommet mange nye oversættelser af gamle sci-fi-klassikere i disse år.
 Teksten, jeg valgte, var et uddrag af begyndelsen af i Frank Herberts roman Dune, udgivet i 1965 og oversat i 1978 til dansk af Niels Søndergaard.
Teksten, jeg valgte, var et uddrag af begyndelsen af i Frank Herberts roman Dune, udgivet i 1965 og oversat i 1978 til dansk af Niels Søndergaard.
Herfra fik jeg ChatGPT, specifikt GPT-4 Omni-modellen, til at generere tre oversættelser. Hver oversættelse var genereret ved brug af forskellige vejledninger, som jeg gav chatbotten. Jeg har desuden kigget på BLEU-scorer som en måde at måle kvaliteten på. Jeg analyserede dog kun én af oversættelserne genereret af ChatGPT grundet den begrænsede skrivetid og plads i specialet.
En promptet oversættelse: nu med BLEU-scorer
Til hver prompt inkluderede jeg en basal kommando om at oversætte uddraget fra engelsk til dansk. Den første genererede oversættelse blev promptet ved zero-shot-metoden, som egentlig bare vil sige, at jeg giver en basal kommando om, at chatbotten skal gøre noget, f.eks. at oversætte en tekst fra engelsk til dansk.
Den anden genererede oversættelse blev promptet ved few-shot-metoden, hvor man giver noget vejledning i form af minimum to eksempler på de ‘korrekte’ svar eller måde(r) at gøre noget på, f.eks. ‘gode’ oversættelser. I denne prompt gav jeg således ChatGPT fem eksempler fra Søndergaards egen oversættelse.
Den tredje og sidste genererede oversættelse blev promptet ved, hvad man kan kalde for en udvidet form af persona/rolle-prompting, hvor man giver chatbotten en rolle, f.eks. i dette tilfælde en professionel oversætter. Den udvidede del vil sige, at jeg gav ChatGPT noget ekstra kontekst i form af en beskrivelse af, hvem publikum er, og hvad de forventer af oversættelsen. Jeg kalder denne udvidede form for ”rolle- og oversættelsesbeskrivelse-prompting” (ROB). Pointen med de forskellige prompts er at undersøge, om de kan påvirke kvaliteten af maskinoversættelsen. En måde at undersøge dette på er som sagt med BLEU-scorer.
BLEU-algoritmen, som står for “Bilingual Evaluation Understudy” på engelsk, blev introduceret af Papineni et al. i 2002 som en hurtig, billig og pålidelig måde at måle kvaliteten af maskinoversættelse på [ii]. I stedet for at hyre et menneske til at evaluere kvaliteten kan man få en computer til det.
BLEU-algoritmen sammenligner en maskinoversættelse med en menneskelig oversættelse, for at se hvor identisk maskinoversættelsen er med den menneskelige oversættelse. Den måler dette med et tal fra 0 til 1 (nogle gange sat op til 100), og dette er BLEU-scoren. En score tættere på 0 betyder en mindre identisk oversættelse, mens en score tættere på 1 (el. 100) betyder en mere identisk oversættelse. I undersøgelser fortolkes en score tættere på 0 oftest som en ‘dårlig’ maskinoversættelse og en score tættere på 1 (el. 100) som en ‘god’ maskinoversættelse. Jeg anvendte selv SacreBLEU-algoritmen, som er en udvidet udgave af BLEU. Den har god troværdighed, da den har været genstand for flere evalueringer og desuden har været brugt til en del evalueringer. Og så er den meget brugervenlig.
BLEU-scorerne for de tre oversættelser kan ses i tabel 1 herunder.
Tabel 1
| Zero-shot | ROB | Few-shot |
| 28.98 | 35.2 | 37.12 |
Nu er spørgsmålet så, hvad disse scorer betyder. Hvor tæt på 0 skal scoren være, før maskinoversættelsen er ‘dårlig’? Hvor tæt på 1, før den er ‘god’? Der findes ingen universel retningslinje. Søger man online, får man forskellige svar på, hvad en dårlig og god score er, men generelt fra de forskellige undersøgelser i akademiske artikler ses det, at scorer under og mellem 0.2 og 0.3 (eller 20 og 30) er lave og dermed viser, at maskinoversættelsen er ‘dårlig’ [iii].
Bedømmer man udelukkende kvaliteten ud fra de tre scorer, må det konstateres, at de tre maskinoversættelser ikke er særlig gode. I resten af analysen bliver det tydeligt, at ChatGPT genererer oversættelser, som ligger tæt på kildeteksten, hver gang det er muligt. Søndergaard oversætter omvendt meget frit. Hvis hans oversættelse er referencen for, hvad en god oversættelse er, og det er en fri oversættelse, mens ChatGPTs oversættelser er meget tætte på kildeteksten, så giver de relativt lave scorer mening.
En forskel i oversættelsesstrategier
Jeg valgte som sagt kun at fokusere på én af de tre ChatGPT-genererede oversættelser, nemlig few-shot oversættelsen. Jeg fandt frem til, hvilke oversættelsesstrategier ChatGPTs oversættelse og Søndergaards oversættelse består af, og hvor store eller små procentdele strategierne udgør af oversættelserne. Jeg farvekodede ord og sætninger til hver oversættelsesstrategi og noterede hvor mange ord, hver oversættelse bestod af. Som en reference er tekststykket fra begyndelsen af Dune, altså kildeteksten, på 4.239 ord.
Tabel 2 viser antallet af ord i det første kapitel i Søndergaards oversættelse samt antallet af ord for hver oversættelsesstrategi. Figur 1 viser hvor store (og små) procentdele af oversættelsen, strategierne udgør.
Tabel 2
| Søndergaards oversættelse | Oblik oversættelse | Direkte oversættelse | Parafrasering | Resterende strategier | |
| Antal ord | 4.490 | 2.504 | 1.501 | 429 | 56 |
Figur 1
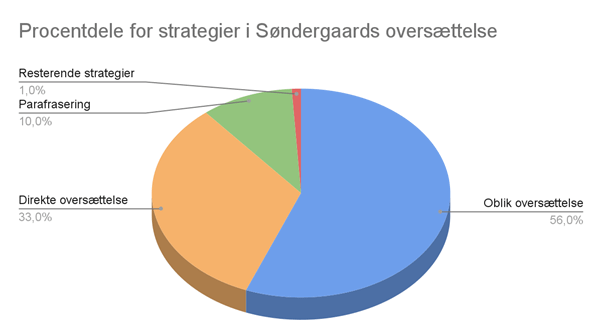
Søndergaards oversættelse er længere end kildeteksten, hvilket også er normen, når man oversætter til sit målsprog. Jeg har beholdt de teoretiske termer i figurerne, men kort forklaret kan det siges, at oblik oversættelse vil sige fri oversættelse, parafrasering er en anden form for fri oversættelse, på en måde endnu friere end oblik, mens direkte oversættelse vil sige at oversætte tæt på kildeteksten, oftest ved at oversætte ord for ord og anvende de mest tilsvarende ækvivalenter på målsproget. De resterende strategier henviser til småting som at beholde f.eks. egennavne, som de optræder i kildeteksten.
De frie oversættelser får teksten til at flyde bedre samtidigt med, at de beholder Dunes unikke identitet. De frie oversættelser ses især i passager, hvor omgivelser og karakterer beskrives. Der er også lidt direkte oversættelse i de passager, men for det meste ses den direkte oversættelse i dialogen, da den for det meste er kort og formel i tonen.
Søndergaards frie oversættelse fokuserer på at bevare det overordnede budskab og de indtryk, man får, når man læser bogen. Det inkluderer typisk at anvende ord, som ikke er direkte ækvivalenter, og at ændre på ordstillingen, så det samtidigt også lyder godt på dansk. Det ville man kalde for en måltekst-orienteret oversættelse, altså at der er fokus på at oversætte frit, så målgruppen får en læseoplevelse, der er letlæselig og justeret til dem.
F.eks. oversætter Søndergaard “The old woman was a witch shadow” til “Der var noget hekseagtigt over den fremmede skygge”. Her omskriver han sætningen i starten og rykker rundt på leddene, f.eks. ved “witch” og “hekseagtigt.” Han oversætter også “Paul fell asleep to dream of an Arrakeen cavern” til “Paul faldt i søvn og drømte om en hule på Arrakis.” Arrakis, også kaldet Dune/Klit, er den ørkenplanet, hvor historien foregår. Her laver Søndergaard om på sidste halvdel af sætningen, så adjektivet “Arrakeen” bliver til selve planeten, Arrakis.
ChatGPT genererer oversættelser, der er det modsatte af Søndergaards frie oversættelser. Tabel 3 viser antallet af ord, og figur 2 viser procentdelene for hver strategi.
Tabel 3
| Few-shot oversættelse | Direkte oversættelse | Oblik oversættelse | Kalker | Resterende strategier | |
| Antal ord | 4.093 | 3.533 | 362 | 147 | 51 |
Figur 2
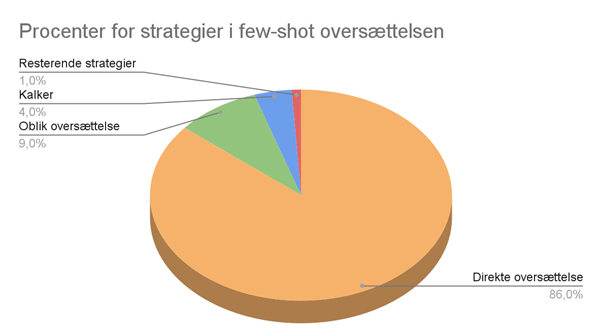
Mens Søndergaards oversættelse er fri, er ChatGPTs oversættelse meget mindre fri. Som sagt genererer ChatGPT direkte oversættelser, når det er muligt. Det resulterer også i kalker og oversættelsesfejl. En kalke er når man oversætter ord for ord, men ender med en oversættelse, der ikke er mundret. Ord for ord i denne kontekst er oftest meget bogstaveligt talt, f.eks. ‘keyboard’ som ‘knap bord’ i stedet for ‘tastatur.’ Det skal dog siges, at kalker ikke altid er dårlige. Der er kontekster, hvor kalker faktisk er gode og passer til oversættelsen.
Oversættelsesfejl er generelt en forkert oversættelse, f.eks. bliver “Master of Assassins” fra kildeteksten til “snigmester” i ChatGPTs oversættelse, hvor det mister ‘morder’ delen. I oversættelsen genereret via ChatGPT er der meget stort fokus på anvendelsen af de tætteste ækvivalenter og ord for ord-oversættelse.
Det ses også, at ChatGPTs oversættelse er kortere end kildetekstens 4.239 ord. Det er ikke helt tydeligt, hvad grunden til dette er, men det er muligt, at de direkte oversættelser på dansk er naturligt kortere end kildetekstens passager og sætninger.
Direkte oversættelse er ikke et problem i sig selv, men det viser sig at blive til et problem i ChatGPTs oversættelse, da der er for meget af det. Selvom oversættelsen (for det meste) er mundret, så mister den Dunes unikke identitet og de indtryk, man får, når man læser kildeteksten. Man kunne sagtens sige, at vi har at gøre med en kildetekst-orienteret oversættelse, hvor målet er at oversætte så tæt på kildeteksten som muligt. Men det skal også gøres klart, at oversættere ofte tager bevidste valg, når det kommer til den måde, de takler deres oversættelser på.
Typisk opfatter vi bevidste valg og intentioner som en menneskelig karakteristik, man ikke finder andre steder end hos mennesker. Men vi har nok aldrig set en maskine komme så tæt på, hvad mennesket er i stand til i forbindelse med kreative processer. Bedømmer man ud fra det kriterium og hvordan GAI fungerer, så tager den ikke beslutninger. Det er en algoritme, som forudsiger, hvad det næste ord er. Alligevel er GAI blevet brugt til at håndtere en kreativ proces som oversættelse samt andre opgaver. Det åbner også for en vigtig diskussion om, hvorvidt AI kan skabe ting og engagere i en kreativ proces ligesom mennesker.
For at give nogle eksempler på ChatGPTs oversættelse, så bliver “The old woman was a witch shadow” til “Den gamle kvinde var som en hekseskygge”. Det eneste ord i denne oversættelse som ikke er en del af ord for ord proceduren, er konjunktionen “som.” Man kunne argumentere for, at den direkte oversættelse sætter fokus på kvinden, mens Søndergaards frie oversættelse gør det mere tydeligt, at det nok handler mere om skyggen, som kvinden kaster. Derudover bliver “Paul fell asleep to dream of an Arrakeen cavern”, til “Paul faldt i søvn og drømte om en grotte i Arrakeen”. Her ses en næsten identisk oversættelse med Søndergaards. Forskellene er “grotte” og en fejloversættelse ved at gøre adjektivet “Arrakeen” til et substantiv. Ordet “grotte” passer fint, men pga. “Arrakeen” er spørgsmålet, om læseren ville forstå, at det handler om en grotte på planeten Arrakis, hvis man ikke efterredigerede.
Kvaliteten og konsekvenserne af GAI-oversættelse
Min undersøgelse viser, at ChatGPT godt kan generere oversættelser af skønlitteratur som (for det meste) giver mening. Der er altså ikke kun oversættelsesfejl. BLEU-scorerne viser også, at det er muligt at prompte sig til en bedre AI-genereret oversættelse. Det er måske åbenlyst, at konkrete eksempler i en prompt resulterer i en bedre maskinoversættelse, især hvis eksemplerne er fra den menneskelige oversættelse, som maskinoversættelsen sammenlignes med. Men der er stadig en tydelig forøgelse af kvaliteten, hvis man eksplicit giver ChatGPT en rolle og kontekst om publikummet. Det bliver dog stadig til en alt for direkte oversættelse, som mister følelserne og de indtryk man får, når man læser kildeteksten. Modsat er Søndergaards oversættelse meget mere fri, hvilket kun hjælper teksten.
Til slut er det også vigtigt at understrege konsekvenserne ved brugen af GAI til at oversætte skønlitteratur i en kommerciel kontekst, altså f.eks. på forlag. Det kan sagtens være, at det er meget billigere at få GAI til at generere oversættelser af skønlitteratur, men der skal stadig bruges tid på at efterredigere og rette fejl, enten ved en redaktør eller en hyret oversætter.
Der er også spørgsmålet om ansvar, når det kommer til brugen af GAI til oversættelse. Hvem skal tage den potentielle kritik fra læsere, som er utilfredse med oversættelsen? Havde en oversætter stået for at oversætte fra bunden, kunne forlaget skyde skylden på oversætteren. Men man kan vel ikke skyde skylden på ChatGPT. Der står jo “ChatGPT kan tage fejl. Vi anbefaler at dobbelttjekke vigtig information”. OpenAI og andre GAI-udbydere prøver at gøre det så tydeligt som muligt, at resultatet ikke nødvendigvis er korrekt eller godt. Der er altså et spørgsmål om ansvar, som kun kan falde på menneskelige aktører. Det er hurtigere og billigere at bruge GAI til at oversætte skønlitteratur, men det er på bekostning af kvaliteten og oversætterens løn.
***
Jeg vil til sidst gerne sige den største tak til min vejleder, Kristian Hvelplund, for den gode vejledning og sparring, der gjorde processen overskuelig.
Noter
[i] Lundberg 2024, Conradsen, Mikkelsen og Mortensen 2024
[ii] Papineni et al. 2002
[iii] Doshi 2021, Kleinmann 2023, Lavie 2011
Kilder
Conradsen, Thomas, Morten Mikkelsen og Elisa Nordgaard Mortensen. 2024. ”Forlag bryder tilskudsregler med maskinoversatte bøger”
Doshi, Ketan. 2021. ”Foundations of NLP Explained – Bleu Score and WER Metrics”
Kleinman, Gal. 2023. ”Demystifying the BLEU Metric: A Comprehensive Guide to MT Evaluation”
Lavie, Alon. 2011. MT summit tutorial. ”Evaluating the Output of MT Systems”
Lunderg, Rasmus Faber. 2024. ”Ulovlig forlagspraksis fik en reprimande – siden er antallet af henvendelser »eksploderet«”
Papineni, Kishore, Salim Roukos, Todd Ward og Wei-Jing Zhu. 2002. ”BLEU: A Method for Automatic Evaluation of MT” I Proceedings of the 40th Annual Meeting on Association for Computational Linguistics (ACL). Philadelphia, Pennsylvania: Association for Computational Linguistics.
***
 Nicolai Thomas Hansen er cand.mag. i engelsk fra Københavns Universitet, hvor han tog oversætterlinjen.
Nicolai Thomas Hansen er cand.mag. i engelsk fra Københavns Universitet, hvor han tog oversætterlinjen.
Hans forskningsinteresser ligger primært inden for oversættelse af skønlitteratur og generativ kunstig intelligens’ evne til at oversætte.
Foto: Anna Oline Anker Ohrt
Super interessant artikel.
Det er interessant at blive hevet op af mølposen efter 47 års forløb og få sin gamle oversættelse sammenlignet med nogle foretaget af samtidige ai’er. Nu er Dune ikke den nemmeste bog at fordanske, og naturligvis er den menneskelige udgave stadig den bedste her i ai-æraens daggry, men lad os nu se, hvordan det ser ud om et par år. Ai-oversættelsen (og -originalitteraturen) er stadig i sin vorden, men jeg er ikke i tvivl om, at fænomenet er kommet for at blive og at de første spæde skridt vil ende i kvantespring, måske endda hurtigere end vi aner – noget forfatteren ikke synes at have overvejet i dette øjebliksbillede.